

使用机器学习 HED 网络优化 SmartCropper 边缘检测
SmartCropper 是我写的一个开源库,主要用于卡片及文档的识别与裁剪 。最近主要对 SmartCropper 进行了两次较大升级,一是升级了 OpenCV 框架到官方最新版,解决了饱为诟病的打包问题(ISSUE), 通过升级 OpenCV 自然也支持了 64 位架构(ISSUE), Google 已经向开发者下发了最后通牒:Support 64-bit architectures。二是完成了一个从初版就躺在 todo-list 里面的 feature:优化智能选区算法。
看过 《Android 端基于 OpenCV 的边框识别功能》 的同学应该知道SmartCropper 是通过 OpenCV 的 Canny 算法识别出照片的边缘线条,然后进行后续处理的,但是 Canny 算法并不能很好的提取出我们想要的边框,如果背景稍微复杂一点就会夹杂着很多非识别物体的边缘线条,对后续的处理提出了很大的挑战。
我们理想中的 Canny 算法效果应该是这样的,输入一张图片能精准的识别出我们想要的边缘线条,后续再配合 OpenCV 的线条检测功能可以很容易得识别出目标物体的位置:

很早之前就看过了 FengJian 大神的文章:《手机端运行卷积神经网络的一次实践 — 基于 TensorFlow 和 OpenCV 实现文档检测功能》,了解到 OpenCV 这种传统算法很快会进入到识别瓶颈,机器学习是一条新思路。
使用篇
网络部分使用的是 FengJian 基于 MobileNetV2 改造的 HED 网络,具体原理后面再说,相关代码位于: SmartCropper/edge_detection/
1.使用/验证模型
使用预训练好的模型识别边框:
python evaluate.py
--input_img test_image/test.jpg
--checkpoint_dir finetuning_model/
--output_img test_image/result.jpg识别结果:

注意:输入网络的图像会 resize 到 256 * 256,网络输出的图像也是 256 * 256,为了方便观测,我后期处理将图片恢复到了原始尺寸,自己测试的时候得到的是 一张 256 * 256 的图片。
这样的识别效果加上 OpenCV 的线段检测已经基本上可以定位到卡片位置了。针对一些识别不好的图片可以在原模型基础上进行 finetuning 。
2.训练数据准备以及预处理
还是以上面这张图片为例子(实际情况下,这张图片已经算识别良好,不需要 finetuning 了),开始之前,需要准备一张根据原图标注好的图片,目前没有好的标注工具(后续有时间可以做一个),暂时使用 Sketch 制作,由于导出的图片线条不是纯白的,需要使用以下脚本进行二值化处理:
python image_threshold.py
--input_img test_image/annotation.jpg
--output_img test_image/annotation_threshold.jpg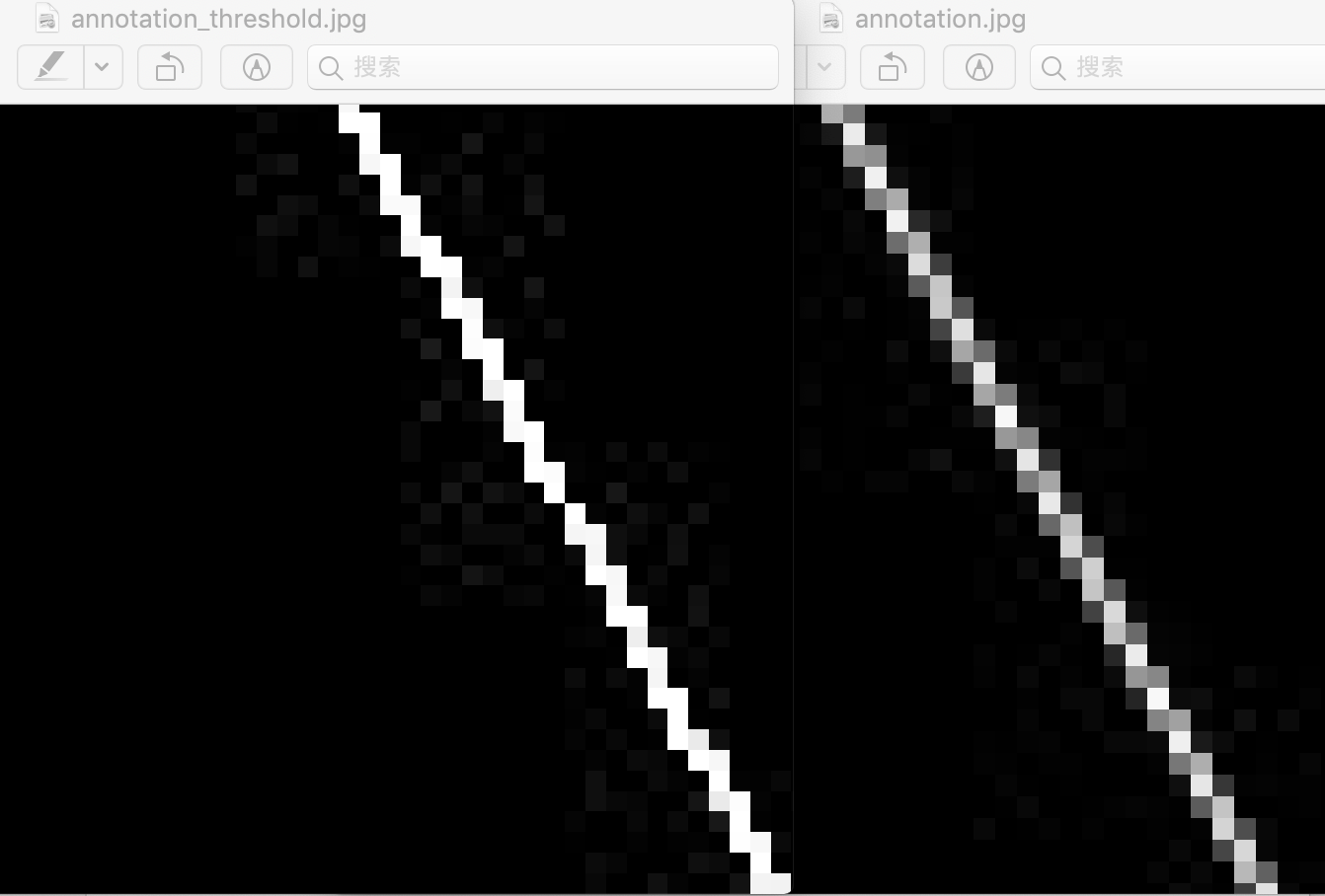
上面是原图和输出图片放大后的对比图,左边是二值化的图片,右边是 Sketch 输出的图片,二值化后的图片只有黑白两种像素,那么这样就得到了一张二值化处理后的标注图:

3.模型训练
输入原始图片,和上方的标注图片开始调优训练:
python finetuning.py
--finetuning_dir finetuning_model/
--checkpoint_dir checkpoint/
--image test_image/test.jpg
--annotation test_image/annotation_threshold.jpg
--iterations 30
--lr 0.0004
--batch_size 1脚本运行完之后会将调优后的模型保存到 –checkpoint_dir 指定的目录下 ,并且在 test_image 目录下生成一张结果图片:fine_tuning_output_img.png
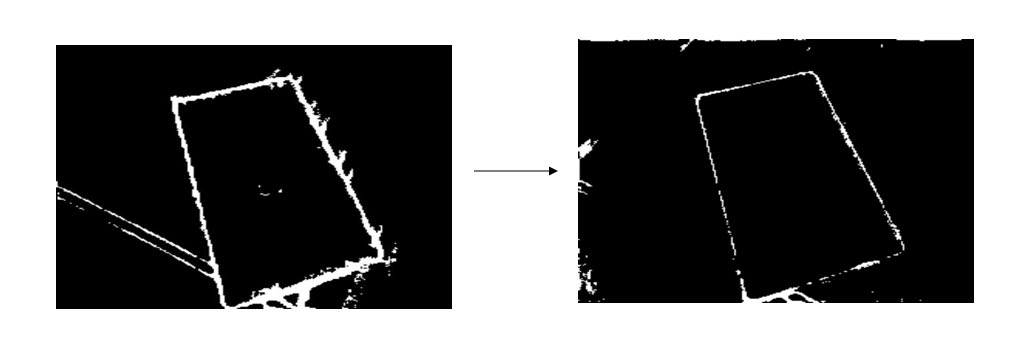
左边是使用原始模型识别的输出的图片,右边是调优之后输出的图片。调优之后识别出的边缘线条正好是我们想要的。
需要特别注意的是输入参数 iterations 不能过大(设置在 15 以内),不然很容易发生过拟合,在调优的图片下拟合良好,但是原来拟合好的图片又不能正常拟合了。
当然也可以通过输入 CSV 文件进行批量训练,批量训练标注是一个很大的工作量,FengJian 的文章提出使用合成的方式生成图片进行训练,他是使用 iOS 模拟器进行合成的,我也在尝试只使用 Python 代码合成。由于单张图片的 finetuning 很容易过拟合,所以更推荐批量训练。参考:hed-tutorial-for-document-scanning
4.模型导出与使用
保存的模型为 ckpt 格式不能直接用于移动端,需要转成 tflite 格式,使用如下脚本进行转换:
python freeze_model.py
--checkpoint_dir checkpoint/
--output_file hed_lite_model_quantize.tflite导出过程中设置了量化处理,生成的 tflite 模型文件只有 346 KB。接着将 tflite 文件复制进 assets 目录下供 TensorFlowLite SDK 加载。SmartCropper 可以用如下方式加载自己的模型文件:
SmartCropper.buildImageDetector(this,"hed_lite_model_quantize.tflite")具体是通过如下方式加载 assets 目录下的 tflite 模型:
MappedByteBuffer tfliteModel = loadModelFile(context, modelFile);
nterpreter.Options tfliteOptions = new Interpreter.Options();
tflite = new Interpreter(tfliteModel, tfliteOptions);
private MappedByteBuffer loadModelFile(Context activity, String modelFile) throws IOException {
AssetFileDescriptor fileDescriptor = activity.getAssets().openFd(modelFile);
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}将输入输出数据包装成 ByteBuffer 之后就可以直接使用模型进行预测了:
public synchronized Bitmap detectImage(Bitmap bitmap) {
if (bitmap == null) {
return null;
}
imgData.clear();
outImgData.clear();
bitmap = Bitmap.createScaledBitmap(bitmap, desiredSize, desiredSize, false);
convertBitmapToByteBuffer(bitmap);
tflite.run(imgData, outImgData);
return convertOutputBufferToBitmap(outImgData);
}以上就是移动端应用机器学习的整个过程,包括数据预处理,训练,验证及使用模型等。
>> 转载请注明来源:使用机器学习 HED 网络优化 SmartCropper 边缘检测
as
nb
nb
可以可以
akm
wc 这, 需求什么基础,才能看懂
simba
tensorflow 是那个版本的,安装最新版的,好多方法报错
pqpo
TensorFlow 版本:1.13.2
west
不错,楼主花了很多心思。
请问SmartCropper库中用到的hed网络模型,你训练了多少张图片?
还有SmartCropper有iOS版本吗
pqpo
原始模型是提取的另一个开源项目,文中有多次提到,我在此基础上进行了调优训练。另外 iOS 版本模型是通用的。
west
请问你用了多少张图片做finetuning?
zhao
你好,文中引用的那个项目和楼主的代码可以在pc端运行吗?
pqpo
python 相关代码可以在pc端运行
zhao
HED检测出边缘后的后处理代码在哪个文件中啊?恢复放大图片不会造成图片失真吗?