

Android 端图像多风格迁移
图像风格迁移是利用机器学习算法实现的图像风格转换, 本篇文章会从风格迁移网络发展历史出发一步步了解风格迁移网络算法,然后带领大家搭建单模型多风格的训练网络,最终给出如何将训练出的模型移植到 Android 端运行的工程化实践。
何为图像风格迁移? 使用机器学习训练特定图片的风格,然后将对应的风格应用到任意图片。效果如下所示:

风格迁移在移动端的最佳实践:Prisma

风格迁移网络发展史
《A Neural Algorithm of Artistic Style》:第一代风格迁移网络风格化的过程是一个训练过程,输入风格图片与内容图像经过训练生成风格迁移图片。经过训练降低内容损失与风格损失,从而得到一张即保证内容又拥有特定风格的图片。缺点显而易见,速度慢!但是确奠定了之后风格迁移的基础。
《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》:之后是称为快速风格迁移的网络,在上一代的基础上增加了转换网络,通过训练转换网络的参数,可以达到一个模型风格化任意图片的目的,由于这是一次正向传播的过程,速度相比上一代着实提高了许多,同样使用训练好的 VGG 网络进行特征提取,经过训练降低内容损失与风格损失。但是这个网络只能产生一种类型风格的图片,如果要支持多风格需要训练多个模型。
《A Learned Representation For Artistic Style》:然后在上一代的基础上发展出了支持多风格的快速迁移网络,网络结构与上一代基本一致,最大的不同是使用 Conditional Instance Normalization 层来代替了原来的 Batch Normalization,前者可以理解为是多个 Batch Normalization 层的合并,根据输入的风格选取特定的 Batch Normalization 参数。该模型的优点是单个模型支持多种风格,速度快,模型小;但是只能支持预训练好的若干模型。
《Meta Networks for Neural Style Transfer》:最后还有一种支持任意风格任意图像的风格迁移网络,这种网络更进一步,引入了 MetaNet,其中转换网络 Transform Net 的一部分参数是 MetaNet 生成的,一部分参数是训练产生的。最终能输出任意风格与内容图像的风格化图片。缺点是模型较大,网络较复杂,不太适合于移动端的风格迁移。
经过对比最终选择更适合移动端的第三种风格迁移网络。
原理
单风格迁移与多风格迁移的模型结构是大体一致的,如下所示:
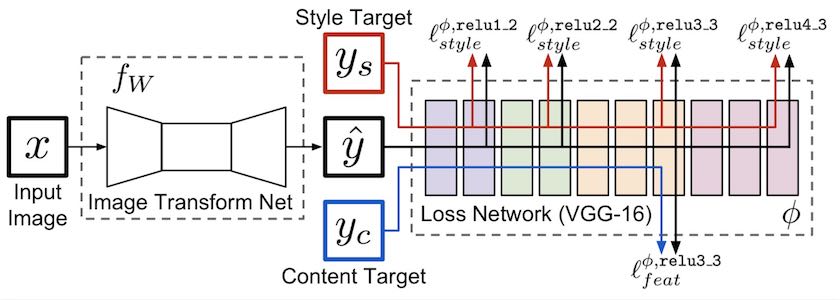
总共包括了转换网络与损失网络,该图中的损失网络使用了 VGG-16 网络,当然也可以使用 VGG-19 等其他图片分类网络。训练阶段训练的是转换网络的参数,其中 VGG-16 网络是训练好的图像分类模型用于提取特征并计算损失。
下面详细讲解一下该图对应的网络模型,其中特征层与损失网络选型有关,此处以 VGG-16 为例:
- 内容图片经过转换网络输出迁移图片 Y
- 迁移图片经过损失网络提取特征层 (relu3_3)
- 原内容图片经过损失网络提取特征层 (relu3_3)
- 使用步骤2、3中的特征层计算内容损失 content_loss
- 风格图片经过损失网络提取特征层(relu1_2、relu2_2、relu3_3、relu4_3)
- 使用第二步中的模型(迁移图片经过损失网络)提取特征层(relu1_2、relu2_2、relu3_3、relu4_3)
- 使用步骤5、6中的特征层计算风格损失 style_loss
- 训练降低内容损失与风格损失:content_loss + style_loss
实现
首先定义转化网络,模型层级与对应参数如下:
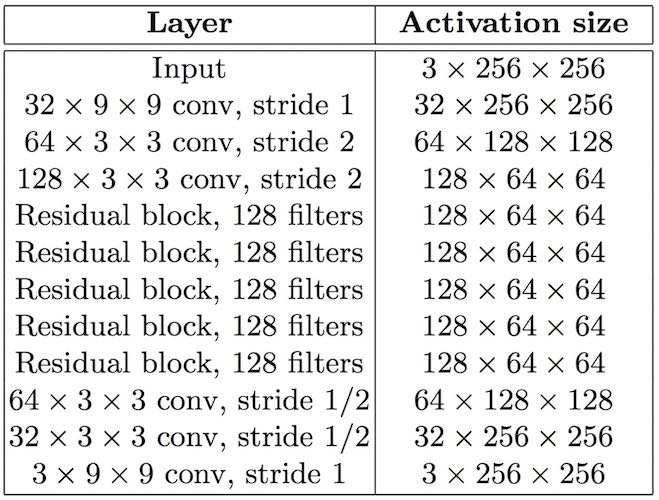
实现转化网络:
def net(x, style_control=None, reuse=False, alpha=1.0):
with tf.variable_scope(tf.get_variable_scope(), reuse=reuse):
x = conv_layer(x, int(alpha * 32), 9, 1, style_control=style_control, name='conv1')
x = conv_layer(x, int(alpha * 64), 3, 2, style_control=style_control, name='conv2')
x = conv_layer(x, int(alpha * 128), 3, 2, style_control=style_control, name='conv3')
x = residual_block(x, int(alpha * 128), 3, style_control=style_control, name='res1')
x = residual_block(x, int(alpha * 128), 3, style_control=style_control, name='res2')
x = residual_block(x, int(alpha * 128), 3, style_control=style_control, name='res3')
x = residual_block(x, int(alpha * 128), 3, style_control=style_control, name='res4')
x = residual_block(x, int(alpha * 128), 3, style_control=style_control, name='res5')
x = conv_tranpose_layer(x, int(alpha * 64), 3, 2, style_control=style_control, name='up_conv1')
x = pooling(x)
x = conv_tranpose_layer(x, int(alpha * 32), 3, 2, style_control=style_control, name='up_conv2')
x = pooling(x)
x = conv_layer(x, 3, 9, 1, relu=False, style_control=style_control, name='output')
preds = tf.nn.sigmoid(x) * 255.
return preds最后的损失函数使用 sigmoid ,它的取值范围是0-1,所以需要乘以 255 转化为颜色值。
每一层的具体实现如下:
def conv_layer(net, num_filters, filter_size, strides, style_control=None, relu=True, name='conv'):
with tf.variable_scope(name):
b,w,h,c = net.get_shape().as_list()
weights_shape = [filter_size, filter_size, c, num_filters]
weights_init = tf.get_variable(name, shape=weights_shape, initializer=tf.truncated_normal_initializer(stddev=.01))
strides_shape = [1, strides, strides, 1]
p = int((filter_size - 1) / 2)
if strides == 1:
net = tf.pad(net, [[0, 0], [p, p], [p, p], [0, 0]], "REFLECT")
net = tf.nn.conv2d(net, weights_init, strides_shape, padding="VALID")
else:
net = tf.nn.conv2d(net, weights_init, strides_shape, padding="SAME")
net = conditional_instance_norm(net, style_control=style_control)
if relu:
net = tf.nn.relu(net)
return net
def conv_tranpose_layer(net, num_filters, filter_size, strides, style_control=None, name='conv_t'):
with tf.variable_scope(name):
b, w, h, c = net.get_shape().as_list()
weights_shape = [filter_size, filter_size, num_filters, c]
weights_init = tf.get_variable(name, shape=weights_shape, initializer=tf.truncated_normal_initializer(stddev=.01))
batch_size, rows, cols, in_channels = [i.value for i in net.get_shape()]
new_rows, new_cols = int(rows * strides), int(cols * strides)
new_shape = [batch_size, new_rows, new_cols, num_filters]
tf_shape = tf.stack(new_shape)
strides_shape = [1,strides,strides,1]
p = (filter_size - 1) / 2
if strides == 1:
net = tf.pad(net, [[0, 0], [p, p], [p, p], [0, 0]], "REFLECT")
net = tf.nn.conv2d_transpose(net, weights_init, tf_shape, strides_shape, padding="VALID")
else:
net = tf.nn.conv2d_transpose(net, weights_init, tf_shape, strides_shape, padding="SAME")
net = conditional_instance_norm(net, style_control=style_control)
return tf.nn.relu(net)
def residual_block(net, num_filters=128, filter_size=3, style_control=None, name='res'):
with tf.variable_scope(name+'_a'):
tmp = conv_layer(net, num_filters, filter_size, 1, style_control=style_control)
with tf.variable_scope(name+'_b'):
output = net + conv_layer(tmp, num_filters, filter_size, 1, style_control=style_control, relu=False)
return output层级最后都使用了归一化函数 conditional_instance_norm,这正是多风格迁移网络与单风格迁移网络的不同之处,单风格迁移网络使用的归一化实现如下:
def instance_norm(net, train=True, name='in'):
with tf.variable_scope(name):
batch, rows, cols, channels = [i.value for i in net.get_shape()]
var_shape = [channels]
mu, sigma_sq = tf.nn.moments(net, [1,2], keep_dims=True)
shift = tf.get_variable('shift', shape=var_shape, initializer=tf.constant_initializer(0.))
scale = tf.get_variable('scale', shape=var_shape, initializer=tf.constant_initializer(1.))
epsilon = 1e-3
normalized = (net-mu)/(sigma_sq + epsilon)**(.5)
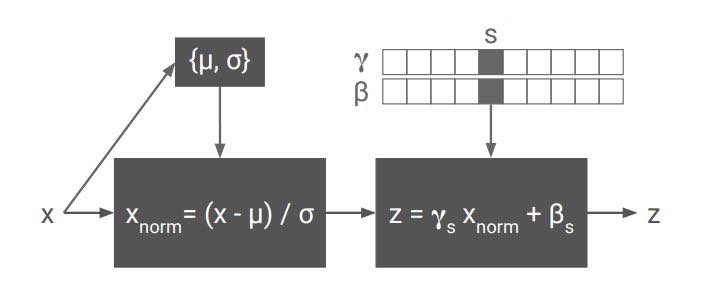
return scale * normalized + shift使用 tf.nn.moments 计算输入层的平均数与方差,然后将输入层减去平均数除以方差,最后开根号实现了输入层的归一化。最后针对归一化的结果乘以 scale 加上 shift: scale * normalized + shift,其中 scale 与 shift 是需要经过训练的参数(有些文中使用 gamma、beta 作为此处参数)。
多风格迁移的区别就在于,有多少风格就存在多少对 scale, shift 参数(对应图中的 gamma、beta ),然后根据风格图位置选取对应参数,所以内置训练风格越多模型会越大,如下图所示
conditional_instance_norm 的实现方式如下:
def conditional_instance_norm(net, style_control=None, name='cond_in'):
with tf.variable_scope(name):
batch, rows, cols, channels = [i.value for i in net.get_shape()]
mu, sigma_sq = tf.nn.moments(net, [1,2], keep_dims=True)
var_shape = [channels]
shift = []
scale = []
for i in range(style_control.shape[0]):
with tf.variable_scope('{0}'.format(i) + '_style'):
shift.append(tf.get_variable('shift', shape=var_shape, initializer=tf.constant_initializer(0.)))
scale.append(tf.get_variable('scale', shape=var_shape, initializer=tf.constant_initializer(1.)))
shift = tf.convert_to_tensor(shift)
scale = tf.convert_to_tensor(scale)
epsilon = 1e-3
normalized = (net-mu)/(sigma_sq + epsilon)**(.5)
idx = tf.where(tf.not_equal(style_control, tf.constant(0, dtype=tf.float32)))
style_select = tf.gather(style_control, idx)
scale_select = tf.gather_nd(scale, idx)
shift_select = tf.gather_nd(shift, idx)
style_scale = tf.reduce_sum(scale_select * style_select, axis=0)
style_shift = tf.reduce_sum(shift_select * style_select, axis=0)
style_sum = tf.reduce_sum(style_control)
style_scale = style_scale / style_sum
style_shift = style_shift / style_sum
output = style_scale * normalized + style_shift
return output其中输入的 style_control 是 one-hot 格式的数据代表具体哪个风格。例如总共有 5 种风格,训练第一种的时候 style_control 为 [1, 0, 0, 0, 0]。
然后定义损失网络,这里选取 VGG-19 网络,其中池化层使用平均池化而非最大池化,定义网络并且加载训练好的模型:
def net(input_image, data):
layers = (
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
'relu5_3', 'conv5_4', 'relu5_4'
)
weights = data['layers'][0]
net = {}
current = input_image
net['input'] = input_image
for i, name in enumerate(layers):
kind = name[:4]
if kind == 'conv':
kernels, bias = weights[i][0][0][0][0]
kernels = np.transpose(kernels, (1, 0, 2, 3))
bias = bias.reshape(-1)
current = _conv_layer(current, kernels, bias)
elif kind == 'relu':
current = tf.nn.relu(current)
elif kind == 'pool':
current = _pool_layer(current)
net[name] = current
return [net['relu1_1'], net['relu2_1'], net['relu3_1'], net['relu4_1'], net['relu5_1'], net['relu4_2']]
def _conv_layer(input, weights, bias):
conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1), padding='SAME')
return tf.nn.bias_add(conv, bias)
def _pool_layer(input):
# return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),
return tf.nn.avg_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),
padding='SAME')值得注意的是,由于损失网络不参与训练,参数需要固定。此处的入参 data 是训练好的模型,需要提前下载并载入:
weights = scipy.io.loadmat('net/vgg19.mat')两个网络已经搭建完成,接着定义内容输入、风格输入、迁移输出:
# content_input
content_input = tf.placeholder(tf.float32, shape=batch_shape, name='content_input')
# style_input
style_img = get_img(style_target[style_index])
style_input = tf.constant((style_img[np.newaxis, ...]), dtype=tf.float32)
# output
style_control = [1 if i == style_index else 0 for i in range(style_num)]
transform_output = transform_net.net(content_input, alpha=alpha,
style_control=tf.constant(style_control, dtype=tf.float32))然后将原图,风格图,迁移图均减去颜色均值再输入到损失网络(vgg-19)中:
vgg_mean = tf.constant(np.array([123.68, 116.779, 103.939]).reshape((1, 1, 1, 3)), dtype='float32')
content_feats = vgg.net(content_input - vgg_mean, weights)
style_feats = vgg.net(style_input - vgg_mean, weights)
transform_feats = vgg.net(transform_output - vgg_mean, weights)通过损失网络的特征输出计算内容损失:
c_loss = content_weight * euclidean_loss(transform_feats[-1], content_feats[-1])
def euclidean_loss(input_, target_):
b,w,h,c = input_.get_shape().as_list()
return 2 * tf.nn.l2_loss(input_- target_) / b/w/h/c其中输入参数分别取得是内容图与迁移图经过 vgg-19 网络的特征层 relu4_2 , content_weight 为内容损失占比系数1.5,可自行调节。
通过损失网络的特征输出计算风格损失:
s_loss = style_weight * sum([style_loss(transform_feats[i], style_feats[i]) for i in range(5)])
def style_loss(input_, style_):
b,h,w,c = input_.get_shape().as_list()
input_gram = gram_matrix(input_)
style_gram = gram_matrix(style_)
return 2 * tf.nn.l2_loss(input_gram - style_gram)/b/c/c
def gram_matrix(net):
b,h,w,c = net.get_shape().as_list()
feats = tf.reshape(net, (b, h*w, c))
feats_T = tf.transpose(feats, perm=[0,2,1])
grams = tf.matmul(feats_T, feats) / h/w/c
return grams计算风格损失的输入是风格图与迁移图经过 vgg 网络的特征层:relu1_1, relu2_1, relu3_1, relu4_1,计算各层的 gram 矩阵,所有特征层的损失相加,最终得出风格损失。
为了使图像更加平滑还加入了全变差正则,最后所有损失相加得到最终的损失函数:
def total_variation(preds):
# total variation denoising
b,w,h,c = preds.get_shape().as_list()
y_tv = tf.nn.l2_loss(preds[:,1:,:,:] - preds[:,:w-1,:,:])
x_tv = tf.nn.l2_loss(preds[:,:,1:,:] - preds[:,:,:h-1,:])
tv_loss = 2*(x_tv + y_tv)/b/w/h/c
return tv_loss
tv_loss=total_variation_weight*total_variation(transform_output)
loss = c_loss + s_loss + tv_loss然后定义优化器,降低总损失:
t_vars = tf.trainable_variables()
var_list = [var for var in t_vars if '{0}'.format(style_index) + '_style' in var.name]
print(var_list)
if style_index == 0:
train_opt = tf.train.AdamOptimizer(learning_rate, momentum).minimize(loss)
else:
train_opt = tf.train.AdamOptimizer(learning_rate, momentum).minimize(loss, var_list=var_list)这里做了个特殊判断,如果是首次训练优化所有参数,之后固定卷积核参数只优化 conditional_instance_norm 层的参数。
最后分 batch 训练即可得到最终的模型:
with tf.Session() as session:
writer_train = tf.summary.FileWriter(tensorboard_dir, session=session)
writer_train.add_graph(session.graph)
session.run(tf.global_variables_initializer())
saver = tf.train.Saver(var_list=t_vars)
checkpoint_file = tf.train.latest_checkpoint(checkpoint_dir)
if checkpoint_file:
print('restore checkpoint: {}'.format(checkpoint_file))
saver.restore(session, checkpoint_file)
for epoch in range(epochs):
num_examples = len(content_targets)
iterations = 0
while iterations * batch_size < num_examples:
start_time = time.time()
curr = iterations * batch_size
step = curr + batch_size
content_batch = np.zeros(batch_shape, dtype=np.float32)
for j, img_p in enumerate(content_targets[curr:step]):
content_batch[j] = get_img(img_p, batch_shape[1:]).astype(np.float32)
iterations += 1
assert content_batch.shape[0] == batch_size
feed_dict = {
content_input: content_batch
}
global_step += 1
session.run(train_opt, feed_dict=feed_dict)
if iterations % 10 == 0:
summary = session.run(summary_merge, feed_dict=feed_dict)
writer_train.add_summary(summary, global_step=global_step)
writer_train.flush()
end_time = time.time()
delta_time = end_time - start_time
print("%s, batch time: %s" % (global_step, delta_time))
if iterations > 0 and iterations % 100 == 0:
save_model(saver, session)
save_model(saver, session)
print('train style end: {}'.format(style_index))训练过程拥有很大的计算量,推荐使用 TensorFlow-gpu 版本进行训练。我个人是在 Google Cloud Platform 上申请的机器训练的,首次使用赠送 $300。
为了方便 Android 端移植,重新实现正向传播,并保存为 pb 格式:
style_index = 0
style_target = glob.glob(style_dir)
style_num = len(style_target)
style_control_array = [1 if i == style_index else 0 for i in range(style_num)]
print('style control: {}'.format(style_control_array))
img_data = get_img(transfer_image_file, (transfer_image_size, transfer_image_size, 3))
im_input_4d = img_data[np.newaxis, ...]
im_b, im_h, im_w, im_c = np.shape(im_input_4d)
img = tf.placeholder(tf.float32, [1, transfer_image_size, transfer_image_size, 3], name='input')
style_control = tf.placeholder(tf.float32, [style_num], name='style_num')
with tf.Session() as sess:
preds = transform_net.net(img, style_control=style_control, alpha=alpha)
print([node.name for node in sess.graph.as_graph_def().node])
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
checkpoint_file = tf.train.latest_checkpoint(checkpoint_dir)
if checkpoint_file:
print('restore checkpoint: {}'.format(checkpoint_file))
saver.restore(sess, checkpoint_file)
output = tf.gather(preds, 0, name="out_img")
out = sess.run(output, feed_dict={img: im_input_4d, style_control: style_control_array})
scm.imsave(os.path.join(os.path.abspath(os.path.dirname(__file__)), 'transfer.jpg'), out)
constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def, ['out_img'])
with tf.gfile.GFile('./model.pb', mode='wb') as f:
f.write(constant_graph.SerializeToString())先加载了前面训练好的 ckpt 模型,最终将模型固化为 pb 格式。其中输入为图像像素rgb通道数组(input),风格图片类型位置(style_num);输出为迁移图像的rgb通道数组(out_img)。
模型移植
通过上述步骤产生的模型大小约为 8M 左右,可以通过模型量化减小模型。何为模型量化?一般情况下编写的模型都是以 float32 作为存储单位,在尽量不影响模型准确率的情况下可以使用更简单的数值类型进行计算,既减小了模型大小又加快了计算速度。一般使用 8 位量化,理论上可以将模型减少 4 倍。参考:Reducing Core ML 2 Model Size by 4X Using Quantization in iOS 12
目前 TensorFlow 新版本的量化工具貌似只能量化成 tflite 格式,但是在量化的过程中失败了,提示有不支持的 op,所以只能退而求其次使用 TensorFlow mobile 而不是 TensorFlow Lite,然后我是使用老版本 TensorFlow 的 tools 目录下的工具量化的。
python /tensorflow/tools/quantization/quantize_graph.py --output_node_names=out_img --output=XXX --mode=eightbit --input=XXX
经过量化模型缩小到 2 M,支持 16 种风格的转化。
将模型文件拷贝到 Android 工程的 assets 目录下,并且集成 TensorFlow mobile:
implementation 'org.tensorflow:tensorflow-android:1.13.1'Android 代码实现:
public Bitmap stylizeImage(Bitmap bitmap, int model) {
Log.w("launched", "stylized in tensor module");
TensorFlowInferenceInterface inferenceInterface = new TensorFlowInferenceInterface(context.getAssets(), MODEL_FILE);
bitmap = Bitmap.createScaledBitmap(bitmap, desiredSize, desiredSize, false);
bitmap.getPixels(intValues, 0, bitmap.getWidth(), 0, 0, bitmap.getWidth(), bitmap.getHeight());
long time = System.currentTimeMillis();
getBitmapPixels(bitmap, floatValues);
Log.w(TAG, "getBitmapPixels time:" +
(System.currentTimeMillis() - time));
for (int i = 0; i < NUM_STYLES; ++i) {
styleVals[i] = 0f;
}
styleVals[model] = 1f;
time = System.currentTimeMillis();
// Copy the input data into TensorFlow.
Log.w("tensor", "Width: " + bitmap.getWidth() + ", Height: " + bitmap.getHeight());
inferenceInterface.feed(INPUT_NODE, floatValues, 1, bitmap.getWidth(), bitmap.getHeight(), 3);
inferenceInterface.feed(STYLE_NODE, styleVals, NUM_STYLES);
inferenceInterface.run(new String[]{OUTPUT_NODE}, false);
inferenceInterface.fetch(OUTPUT_NODE, floatValues);
Log.w(TAG, "run model time:" + (System.currentTimeMillis() - time));
time = System.currentTimeMillis();
mergePixels(floatValues, intValues);
bitmap.setPixels(intValues, 0, bitmap.getWidth(), 0, 0, bitmap.getWidth(), bitmap.getHeight());
Log.w(TAG, "return bitmap time:" + + (System.currentTimeMillis() - time));
return bitmap;
}先通过模型路径初始化 TensorFlowInferenceInterface,获取 Bitmap 的像素值,通过 getBitmapPixels 方法转化成 rgb 三通道的数组,然后根据风格图片的位置初始化 one-hot 形式的 style_num 输入。最后得出风格化的输出,由于输出是 rgb 三通道数组,然后通过 mergePixels 方法转化成 int 数组。出于性能考虑,两个数组遍历处理(getBitmapPixels、mergePixels)统一由 native 实现,速度提升一个数量级,实现如下:
extern "C" JNIEXPORT void
JNICALL
Java_me_pqpo_awesomeimage_ImageStyle_mergePixels(JNIEnv *env, jobject obj, jfloatArray pix_, jintArray mergedPix_) {
jfloat *pix = env->GetFloatArrayElements(pix_, NULL);
jint *mergedPix = env->GetIntArrayElements(mergedPix_, NULL);
int len = env->GetArrayLength(mergedPix_);
for (int i = 0; i < len; ++i) {
mergedPix[i] =
0xFF000000
| (((int) (pix[i * 3])) << 16)
| (((int) (pix[i * 3 + 1])) << 8)
| ((int) (pix[i * 3 + 2]));
}
return;
}
extern "C" JNIEXPORT void
JNICALL
Java_me_pqpo_awesomeimage_ImageStyle_getBitmapPixels(JNIEnv *env, jobject obj, jobject srcBitmap, jfloatArray pix_) {
jfloat *pix = env->GetFloatArrayElements(pix_, NULL);
void *srcPixels = 0;
AndroidBitmapInfo srcBitmapInfo;
try {
AndroidBitmap_getInfo(env, srcBitmap, &srcBitmapInfo);
AndroidBitmap_lockPixels(env, srcBitmap, &srcPixels);
uint32_t srcHeight = srcBitmapInfo.height;
uint32_t srcWidth = srcBitmapInfo.width;
for (int i = 0; i < srcHeight * srcWidth; ++i) {
int val = static_cast<int*>(srcPixels)[i];
pix[i * 3] = static_cast<jfloat>(((val) & 0xFF));
pix[i * 3 + 1] = static_cast<jfloat>(((val >> 8) & 0xFF));
pix[i * 3 + 2] = static_cast<jfloat>(((val >> 16) & 0xFF));
}
AndroidBitmap_unlockPixels(env, srcBitmap);
return;
} catch (...) {
AndroidBitmap_unlockPixels(env, srcBitmap);
jclass je = env->FindClass("java/lang/Exception");
env -> ThrowNew(je, "unknown");
return;
}
return;
}使用方法:
ImageStyle imageStyle = new ImageStyle(MainActivity.this);
Bitmap bitmap = BitmapFactory.decodeResource(MainActivity.this.getResources(), R.mipmap.tubingen);
Bitmap styleBitmap = imageStyle.stylizeImage(bitmap, 0);以上代码在 Android 端风格化一张 1024*1024 的图片大概需要 18s,下面通过裁剪网络的方式进一步缩小模型体积,提升转化速度。最终风格化一张 1024*1024 的图片时间压缩到了 5s。
网络裁剪
主要思路是减小卷积核宽度,删减残差层,下面是裁剪过的转化网络,参考:https://github.com/fritzlabs/fritz-style-transfer
def net_small(x, style_control=None, reuse=False, alpha=1.0):
with tf.variable_scope(tf.get_variable_scope(), reuse=reuse):
x = conv_layer(x, int(alpha * 32), 9, 1, style_control=style_control, name='conv1')
x = conv_layer(x, int(alpha * 32), 3, 2, style_control=style_control, name='conv2')
x = conv_layer(x, int(alpha * 32), 3, 2, style_control=style_control, name='conv3')
x = residual_block(x, int(alpha * 32), 3, style_control=style_control, name='res1')
x = residual_block(x, int(alpha * 32), 3, style_control=style_control, name='res2')
x = residual_block(x, int(alpha * 32), 3, style_control=style_control, name='res3')
x = conv_tranpose_layer(x, int(alpha * 32), 3, 2, style_control=style_control, name='up_conv1')
x = pooling(x)
x = conv_tranpose_layer(x, int(alpha * 32), 3, 2, style_control=style_control, name='up_conv2')
x = pooling(x)
x = conv_layer(x, 3, 9, 1, relu=False, style_control=style_control, name='output')
preds = tf.nn.sigmoid(x) * 255.
return preds将每一层卷积层的卷积核宽度减小到了 32 层,删除了两层残差块,并且引入了超参数 alpha 进一步减小卷积核宽度,原作者给出 alpha 值可以减小到 0.3,量化模型大小缩小到了 17kb,实验下来效果损失比较大,大家可以多实验,找出自己能接受的转化效果对应的参数。
参考:
- A Neural Algorithm of Artistic Style
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- A Learned Representation For Artistic Style
- Meta Networks for Neural Style Transfer
- tensorflow / magenta
- Reducing Core ML 2 Model Size by 4X Using Quantization in iOS 12
- [译] A Neural Algorithm of Artistic Style
- Heumi/Fast_Multi_Style_Transfer-tensorflow
- hzy46/fast-neural-style-tensorflow
- fritzlabs / fritz-models
- lengstrom / fast-style-transfer
- MashirosBaumkuchen / Flora
●非常感谢您的阅读,欢迎订阅微信公众号(右边扫一扫)以表达对我的认可与支持,我会在第一时间同步文章到公众号上。当然也可点击下方打赏按钮为我打赏。
●另外也可以支持一下我的副业,扫描右方代购二维码加我好友,不买看看也行。朋友在荷兰读医学博士,我和他合作经营的代购,欧洲正规商店采购,正品保证。
免费分享,随意打赏



ethanhua
手机上体验5秒还是有点多,不过还是很赞
开发者头条
感谢分享!已推荐到《开发者头条》:https://toutiao.io/posts/0v3wya 欢迎点赞支持!使用开发者头条 App 搜索 55960 即可订阅《pqpo》
Nicholas
你好,请问有详细的源代码可以参考一下吗
pqpo
代码基本上都贴在文章里啦,复制一下拼凑拼凑就能跑了
miao
你好,使用tf量化后,输入的维度被固定了,请问你是怎么解决的呢?
pqpo
输入图像的大小本身是固定的
miao
网络是全卷积网络,输入图形大小可以任意的,只是tf量化之后存在维度固定的问题,官方说更新修复这个问题,但是一直没有更新
pqpo
我在写正向传播的时候固定了输入图像的大小:img = tf.placeholder(tf.float32, [1, transfer_image_size, transfer_image_size, 3], name=’input’),
这里直接改成这样?[1, None, None, 3]
illuosion
对于conditional_instance_norm,每个风格都有自己的 scale, shift 参数,但是每个风格训练时使用的权重也就是weights_init 是共享的,第二个风格训练的时候就改变了这个权重,那对于第一个风格来说,训练好的 scale, shift 参数就配不上了
这要怎么解决,我自己训练时,训练过的风格效果会受到影响